Ron Forbes from Xbox.com talks Xbox 360 Kinect and explains in great detail how you become the controller.
"You are the controller." If you've been following the buzz surrounding Kinect, you've probably heard this phrase tossed around. From plugging leaks with your hands and feet in Kinect Adventures! to changing songs with the flick of a wrist in Zune, Kinect opens up a new way to naturally experience your entertainment

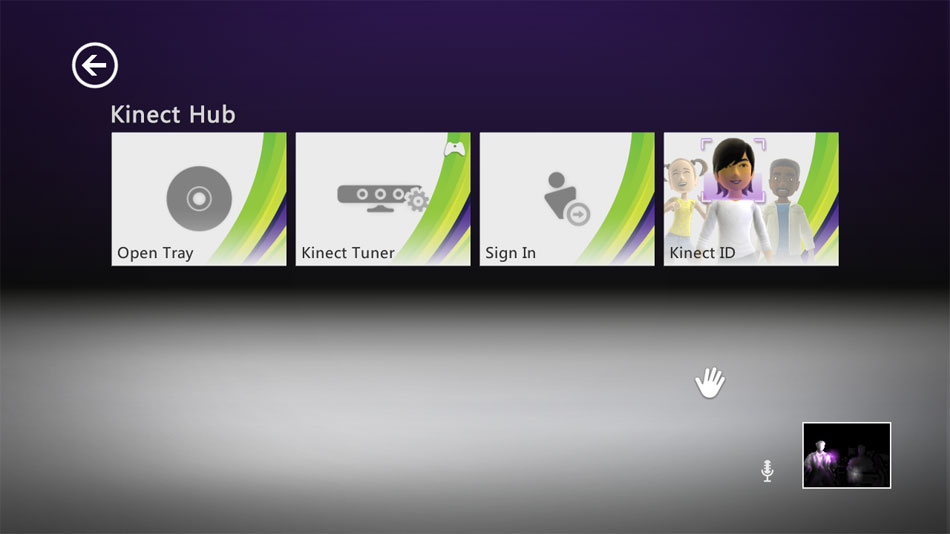
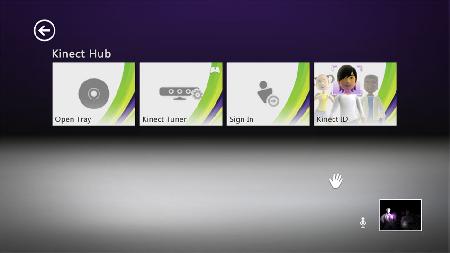
But once you get over the magic of opening the disc tray with the wave of a hand like you're a Jedi, you might start to wonder how it all works under the hood. In this blog post, I'll focus on the secret sauce behind the human tracking system and how it allows game developers to produce Kinect-enabled experiences. Then Arjun Dayal, a program manager on the team, will show you how Kinect enables a gesture-based approach to navigating the Xbox Dashboard and Kinect Hub. But before we get into any of that, lets start with the conceptual principles that guided Kinects development.
Its an Analog World We Live In
Traditional programming is based on sets of rules and heuristics: cause and effect, zero and one, true and false. Fortunately, this approach works well when modeling simple systems with a limited number of inputs and outputs. Take Halo for example (not a simple system by any means, but suitable for proving the point): pushing A causes Master Chief to jump; moving one stick causes him to walk forward; moving another causes him to look up. If A, then B. Unfortunately, the real world is not digital, but analog.

In the analog world, its not just about yes and no, but its about maybe. Its not just about true or false, but its about probability. Think briefly about all of the possible variations of a human waving his hand: the range of physical proportions of the body, the global diversity of environmental conditions, differences in clothing properties, cultural nuances to performing even a simple gesture. Quickly, you end up with a search space around 10^23, an unrealistic problem domain to solve through conditional-based programming.
We knew early on that we had to invent a new way of approaching this problem, one that works like the human brain does. When you encounter someone in the world, your brain instantly focuses on him and recognizes him based on years of prior training. It doesnt crawl a decision tree hundreds of levels deep to discern one human from another. It just knows. Where a baby would have a hard time telling the two apart, youve learned to do so in a split second. In fact, you could probably make a reasonable guess about their age, gender, ethnicity, mood, or even their identity (but thats a blog post for another day). This is part of what makes us human.
Kinect was created in the same way. It sees the world around it. It focuses on you. And even though its never seen how you wave your hands before, it instantly approximates your movements to the terabytes of information its already learned.
The Kinect Sensor
At the heart of the skeletal tracking pipeline is a CMOS infrared sensor which allows Kinect to perceive the world, regardless of ambient lighting conditions. Think of this as seeing the environment in a monochrome spectrum of black and white: black being infinitely far away and white being infinitely close. The shades of gray in between these two extremes correspond to a physical distance from the sensor. The sensor gathers each point in its field of view and forms it into a depth image that represents the world. A stream of these depth images is produced at a rate of 30 frames per second, creating a real-time 3-D representation of the environment. Another way to think of this is like those pinpoint impression toys that used to be all the rage. By pushing up with your hands (or your face if you were really adventurous), you could create a simple 3-D model of a piece of your body.
Finding the Moving Parts
The next thing Kinect does is to focus on the moving objects most likely to be humans in the image, much like the human eye subconsciously focuses on moving objects that it sees in the world. Later in the pipeline, Kinect will perform a pixel-by-pixel evaluation of the depth image to identify parts of the human body; however, to maintain a responsive refresh rate, this evaluation must be optimized beforehand.
Segmentation is the strategy Kinect uses to separate the humanoid masses from the background, the signal from the noise. Kinect can actively track the full skeletons of up to two human players as well as passively track the shape and position of four passive players at once. In this phase of the pipeline, we create what's called a segmentation mask of each tracked human player in the depth image. This is a modified version of the depth image that has subtracted background objects from the scene such as chairs and pet cats. By sending just the segmentation mask through the rest of the pipeline, we reduce the upcoming computational work that must be done to identify parts of the body.
The Brain Inside Kinect
Here's where the real magic happens. Each pixel of the player segmentation is fed into a machine learning system thats been trained to recognize parts of the human body. This gives us a probability distribution of the likelihood that a given pixel belongs to a given body part. For example, one pixel may have an 80% chance of belonging to a foot, a 60% chance of belonging to a leg, and a 40% chance of belonging to the chest. It might make sense initially to keep the most probable proposal and throw out the rest, but that would be a bit premature. Rather, we send all of these possibilities (called multiple centroid proposals) down the rest of the pipeline and delay this judgment call until the very end.
As a brief aside, you might start to wonder how we taught this brain to recognize body parts. Training this artificial intelligence (called the Exemplar system) was no small feat: terabytes of data were fed into a machine cluster to teach Kinect a pixel-by-pixel technique for identifying arms, legs, and other body parts it sees. The harlequin-looking figures you see here are some of the data points we used to train and test the Exemplar system.
Model Fitting: Creating the Skeleton
The final step in the pipeline is to use the centroid proposals from the previous phase to create a skeleton of the 20 joints that are tracked. For each joint, Kinect considers every pixel that Exemplar proposed as a likely match. This way it has the full context to make the most accurate assessment of where the human actually is. We also do some additional filtering of the output at this model fitting stage to smooth the output and handle special cases like occluded joints.
One of our goals with the skeletal tracking system was to provide an "a la carte" interface to the different outputs of the pipeline. Game developers can use as many or as few of these components to make enjoyable experiences. For instance, you can use just the segmentation map to create some incredible aesthetic effects (Your Shape: Fitness Evolved is a great example of this).
And there you have it, a complete real-time human tracking system to control your games and entertainment. Hopefully, this look inside Kinect has shown you how we enable game developers to make digital sense of the analog world in which we live. Next, Arjun introduces you to the improved Xbox Dashboard and Kinect Hub. He'll show you how the Dashboard and Kinect Hub leverage the depth stream and 20-joint skeleton to create an intuitive gesture-based way to access your games, movies, music, and other entertainment.
Full Story:
www.xbox.com"